Site Search > App Settings > Data Management > Crawler
The SearchStax Site Search solution offers a Crawler add-on for Enterprise clients. The Crawler indexes the pages of your website starting with a single root node. See Crawler Walkthrough for the full procedure.
Enterprise Clients Only!
The Crawler feature is restricted to Enterprise clients only. The following restrictions apply:
The feature is restricted to one crawl per day.
Crawls are limited to 10,000 pages or 100,000 pages per crawl, depending on your contract.
The SearchStax Site Search solution’s Crawler is an add-on connector that finds and indexes all of the pages of a website, making them searchable through a Search App.
The Crawler begins with a root URL and follows page links from there to all connected pages using the same corporate domain, subject to a configurable crawl-depth limitation.
Each Search App can have multiple crawlers, putting multiple websites into a single combined index.
The crawlers automatically refresh the index at a predetermined interval, updating, adding, and deleting index entries as needed.
If the Crawler feature is enabled for your Enterprise account, you’ll find it listed under Site Search > App Settings > Data Management > Crawler in the Navigation Menu:
This link opens the Crawler list, which is initially empty.
Crawler List
A Search App can have one or more Crawlers, each indexing pages from one or more websites.
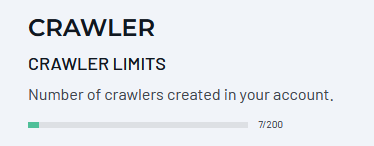
How Many Crawlers Can You Have?
An Enterprise account may be authorized to create several concurrent crawlers. This limit is applied to the account, not to individual Site Search Apps. The progress bar on this screen shows the number of crawlers and the account limit.
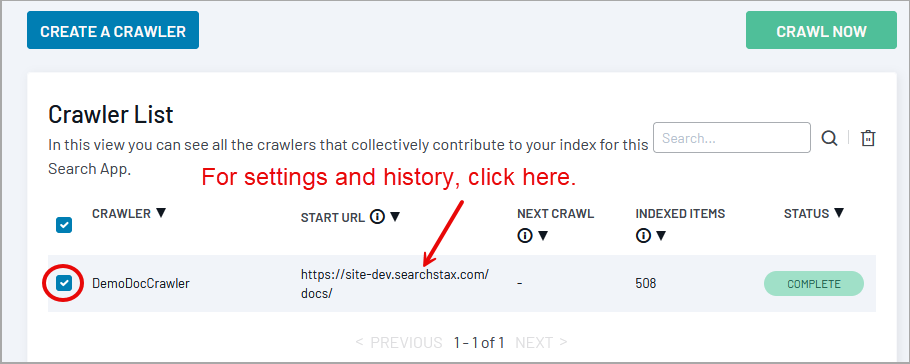
From this list, you can monitor crawler status, open an editor to create or modify a crawler, launch an immediate crawl, or delete a crawler.
When you rerun a crawler, it updates records of existing pages and deletes the records of pages that are no longer reachable. When you delete a crawler, the web pages it found are removed from the index.
To initiate a crawl, check the crawler in the list and use the Crawl Now button.
To view a crawler’s details, settings, and history, click the desired crawler in the list.
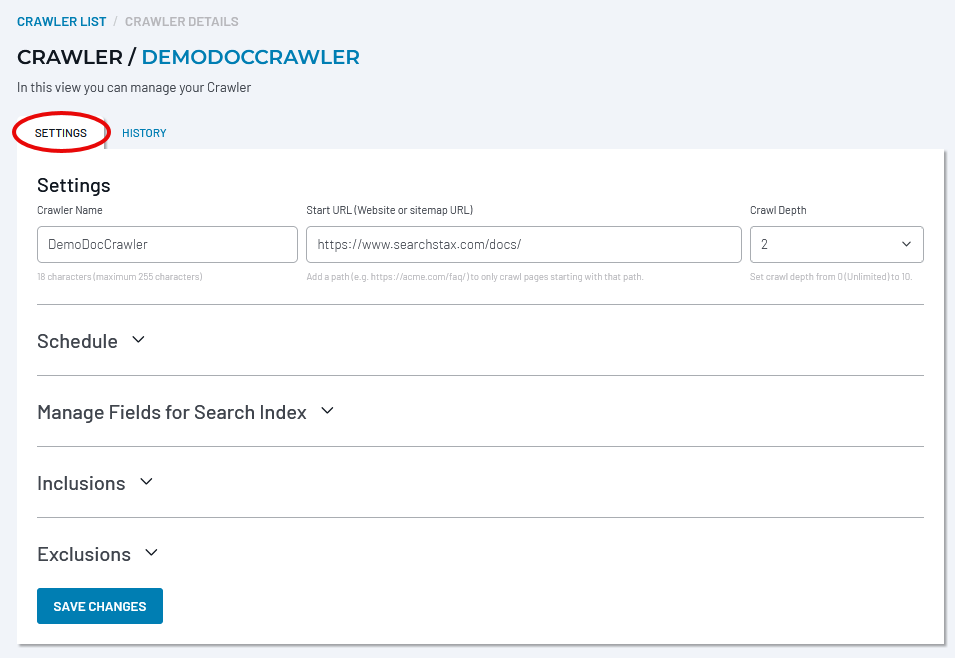
Settings Tab
Clicking on a crawler in the Crawler List takes you to the Crawler Details screen. Select the Settings tab.
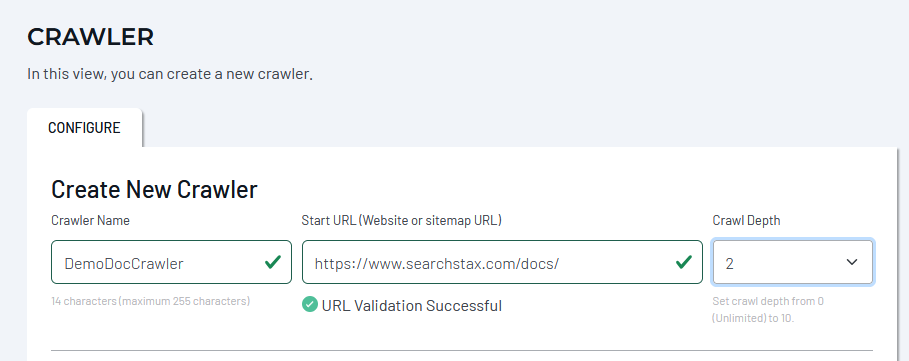
Crawler Name
Each crawler in your SearchStax account must have a unique name. The names can be multi-word, mixed-case, and alphanumeric. Site Search will ignore case when checking for redundant names.
Start URL
The crawler requires a starting or “seed” web page to anchor the crawling process. The crawl follows all the outgoing links from that page recursively until it runs out of pages that have the same DNS domain as the starting page. The crawler will not wander into other domains. Create a second crawler if you want to include pages from another domain in the same index. Your Search App can support more than one, subject to the terms of your contract.
The Start URL can also point to a sitemap file, such as:
https://example.com/sitemap.xml
or a sitemap-index file:
https://example.com/sitemap_index.xml
Crawl Depth
The “crawl depth” is the number of links crawled from the Start URL. It has three defaults, depending on the Start URL:
If the starting page is a sitemap.xml file, the default crawl depth = 1.
If the starting page is a sitemap-index.xml file, the default crawl depth = 2.
Otherwise, the default crawl depth is “0” meaning “unlimited.”
You can manually select a crawl depth of 1 through 10 to customize your crawl.
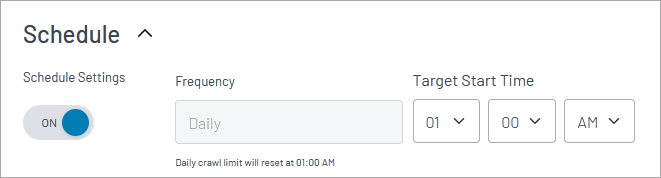
Schedule
When enabled, the crawler repeats its crawl daily at the indicated local time. Subsequent crawls add newly found pages, delete pages that can no longer be found, and refresh the remainder.
Subject to your contract, Site Search will impose a limit of one crawl per day.
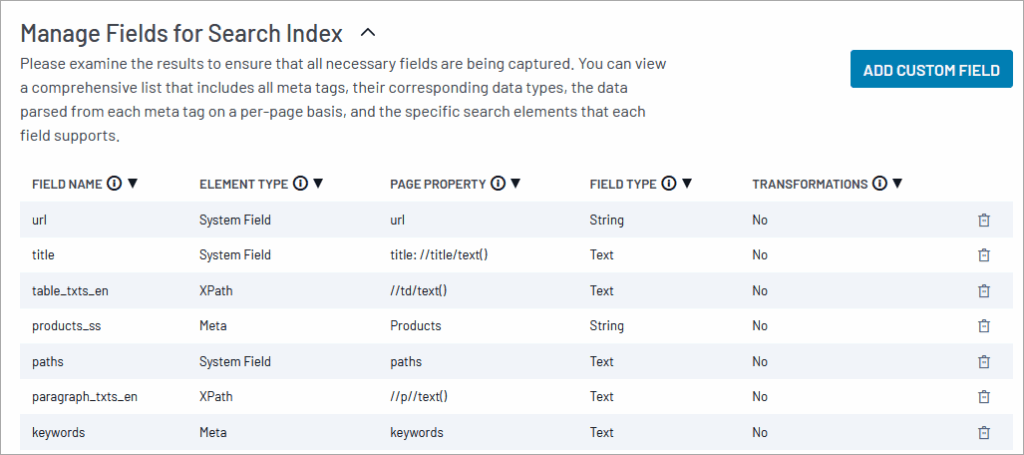
Manage Fields for Search Index
The crawler maps information about a web page to Solr schema fields in the Site Search index. Although the crawler has a default set of mappings, some customization is normal. The Fields table lets you edit and refine your field mappings.
You can delete a field using the in-line trash-can icon in the rightmost column.
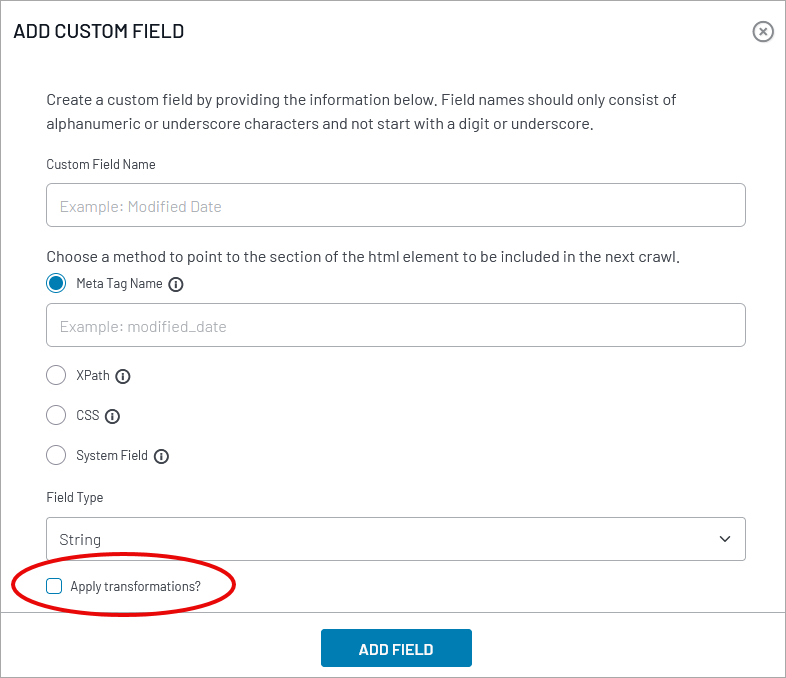
To add a new custom field, click the Add Custom Field button. This opens a field editing form.
Notes on the field options:
Site Search will modify the Custom Field Name to indicate the field type and language. For instance, field “paragraph” will become “paragraph-txt-en” in the list of fields.
Meta Tag Name retrieves the content of a named meta tag in the web page. The default field list includes the “description” and “keywords” meta tags.
XPath uses an XPath formula to scrape the content of HTML tags in the page. For instance, “//p//text()” retrieves the content of all paragraph (p) elements.
CSS lets us input a CSS class selector. The crawler will retrieve the content of all HTML elements that match the selector. For instance, “class~=name” will match any element whose class attribute contains “name” as a separate word within a space-separated list of words.
System offers a droplist of internal Site Search fields about a web page, such as id, title, url, and document_type. Most of these are predefined default fields.
Field Type is a droplist of Solr schema field types: Boolean, Date, Float, Integer, String, and Text. This has implications for how the data is indexed and queried. For instance, a “String” field requires an exact whole-string match, but a “Text” field matches individual words.
The Apply Transformations feature becomes available when defining string and text fields. This makes transformers available to normalize irregular field values during ingestion. See Crawler Transformers in the Help Center.
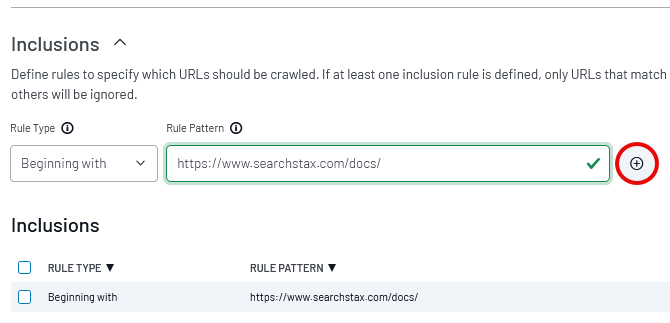
The Crawler will always remain within your DNS domain, but it does not limit itself to the tree below the Start URL. Inclusion rules let you confine the crawler to pages where the page URL contains an explicit substring. When you use Inclusion rules, only URLs that match at least one rule will be crawled.
Rule Pattern: Enter part or all of a URL (or regex pattern) as the basis of an inclusion rule. Site Search will interpret it according to one of the following contexts:
Beginning with: Includes any page with a URL that begins with this string.
Contains: Includes any page containing the indicated substring.
Ending with: Includes any page where the URL ends with this string.
Matching regex: Includes any page where the URL matches the indicated regular expression.
Additional controls:
Plus (+) icon: Click here to add the inclusion to the list of active inclusions.
Exclusions
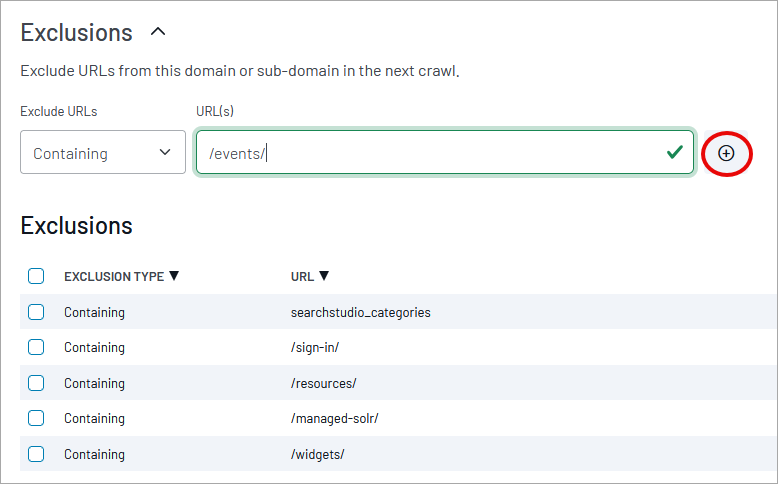
After your initial crawl, experience may show that the Crawler needs to be more limited in scope. Exclusions are rules that prevent the crawler from exploring every branch of your domain.
Exclude URLs: Enter part or all of a URL (or regex pattern) as the basis of an exclusion rule. Site Search will interpret it according to one of the following contexts:
Beginning with: Excludes any page with a URL that begins with this string.
Contains: Excludes any page containing the indicated substring.
Ending with: Excludes any page where the URL ends with this string.
Matching regex: Excludes any page where the URL matches the indicated regular expression.
Additional controls:
Plus (+) icon: Click here to add the exclusion to the list of active exclusions.
To delete an exclusion, check the box on the left of the exclusion and click the trashcan icon.
Inclusion/Exclusion doesn’t work?
The inclusion/exclusion URLs are case-sensitive. You might need multiple rules to cover variations in capitalization.
When Inclusion/Exclusion Conflict
If inclusion rules contradict exclusion rules, the exclusion rules win.
Don’t forget to click the Save Changes button to persist the changes you have made on this screen.
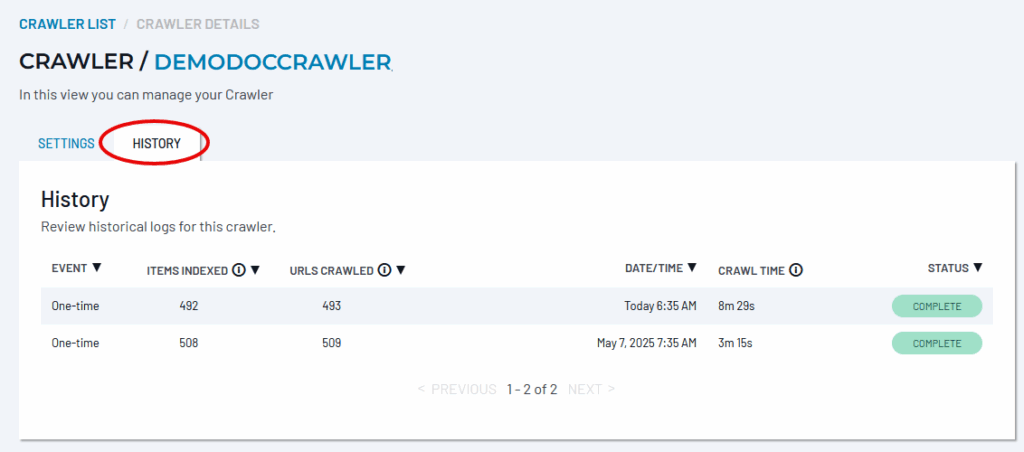
History Tab
The History tab presents summary statistics of crawler runs.
Not all of the discovered links can be crawled successfully, usually because of inappropriate file types. The Items Indexed and URL Crawled columns give a general idea of how successful the crawl was.
File Size Limits
The Crawler enforces the following file size limits:
HTML files: The Crawler ignores and does not download HTML files that are over 1 MB in size. It indexes only the first 100 KB of the file’s content field.
Rich Text Documents: The Crawler ignores and does not download RTF files that are over 1 GB in size. It indexes only the first 100 KB of the file content.