An Index Average Response Time / Request alert is a Threshold Alert that notifies you by email when the mean time spent on an Index Request in a SearchStax Managed Search service deployment exceeds some threshold over a period of some minutes. This creates an Incident in the Managed Search Dashboard.
This condition arises when the system is overloaded, or when the replication mechanism has broken down.
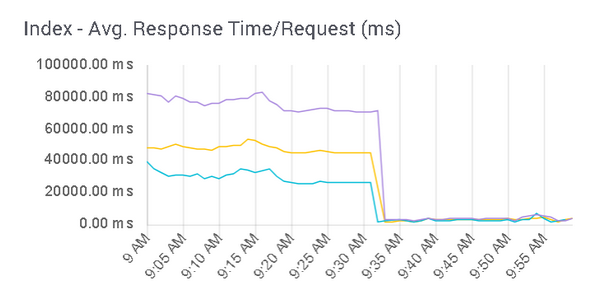
The graph above shows a very sluggish cluster and the impact of a rolling restart.
System Load is Too High
Index Average Response Time / Request alerts can result when the system is under heavy stress. Check the System Load/CPU graphs to evaluate the load. Also, check the Service Graph to see if there is a spike.
This is often associated with a heavy episode of indexing. Solr Admin > Cloud > Tree > Overseer can show if there are too many items queued up. If the alerts are associated with indexing events, consider throttling back the flow of /update messages.
This situation can be relieved by performing a rolling restart to clear the queues. Contact SearchStax Support if you need any help there.
If the issue is because of System load and is consistent, the deployment might need an upgrade.
Replica In Unhealthy State
It is possible for a replica to lose synchronization with the rest of the collection, putting it into “recovery” mode while Zookeeper attempts to rebuild it. A replica in recovery is not available for index updates, which may cause Index Average Response Time / Request errors.

Check the Solr Admin UI > Cloud > Graph to see if all collections are replicated on all solr nodes and are in a healthy state. If there is a problem, contact SearchStax Support for assistance.
Questions?
Do not hesitate to contact the SearchStax Support Desk.