


Solr is one of the leading search platforms for websites, enterprises, and more but Solr is more than just a basic search engine.
What Is Solr?
Apache Solr is an open-source search platform. It offers full text search and real-time indexing for large amounts of content. Solr also provides powerful and customizable queries, filters and search facets, as well as robust scalability and distributed computing support.
Solr can be used as a stand-alone search engine for website, content and keyword search and integrated into larger search and data processing applications through various APIs and deployment methods.
Who is Apache?
The Apache Software Foundation is a non-profit organization that supports and maintains a variety of open-source software packages and platforms including Solr. Apache and the volunteer maintainers for Solr accept contributions from the open-source community for new features, bug fixes, security updates and other improvements to the platform. Apache maintains, hosts and distributes Solr and makes the search platform available under the Apache License v2.0.
What is Lucene?
Lucene is an open-source search engine library maintained by Apache. Lucene is a foundational search engine that includes content indexing and search features.
Search platforms such as Solr are built on top of Lucene and extend the core indexing and search features. They also add additional functions such as faceting, filtering, geospatial search and analytics. Solr also includes powerful APIs, data replication features, caching, and administration interfaces for managing, scaling and deploying Solr search capabilities.

Lucene, Solr and Elasticsearch
The Lucene search engine is used by several search platforms including Solr, Elasticsearch, OpenSearch and others. Each platform adds different features, functionality and support on top of the Lucene search engine.
Loading..........
The Data is Not Available
Solr vs. Relational Databases
Solr was designed as a search engine first, so many of the querying methods, data indexing and underlying infrastructure are designed to support keyword search across diverse textual content. Relational databases on the other hand, are optimized for querying fields in a fixed database schema, joining disparate datasets and quickly updating specific records.
Organizations will need to determine if and when to use Solr or a relational database system. Often, they will use both together. The choice depends on their infrastructure and system needs. Many content management systems, such as Sitecore and Drupal, use Solr for search functionality and relational databases for core CMS feature and state storage.
Managing the infrastructure needed to support relational databases or Solr may be another challenge when planning data storage and querying systems. Organizations can choose to run their data storage infrastructure in-house or use a managed database or search provider to host their search infrastructure.
How Does Solr Work?
Like most search platforms, Solr creates an index of documents to search. This index is made from source content such as websites, PDFs and Word documents. Users can search this index to find documents that match specific keywords, filters or other search parameters. Solr will then rank those documents based on relevancy to the search query and return a complete list of search results.
Let’s take a look at how each of those steps work.
1. Indexing Content
Solr can index and search content from a variety of sources. This includes structured and unstructured formats like websites, long-form text content, diverse data sets and more.
First, content is sent to the Solr API. Then Solr processes that content into keywords, phrases and other data types such as email addresses and phone numbers. Solr assigns a “token” to each unique keyword, phrase, or data and stores those tokens in the search index to track which document contained the various tokens.
2. Querying, Searching and Finding Relevant Documents
Once Solr has processed all content and created a search index, we can begin querying and searching for documents. Solr uses lexical “keyword” search to find matching documents. It does this by processing a search query into keywords, phrases and other tokens. Solr scans the search index for exact matches and “close-enough” matches and creates a list of search results that includes any matching documents.
3. Filtering Search Results
Solr includes powerful and customizable faceting and filtering to further refine search results based on a user’s query. Solr queries can include complex filtering logic and functions that can perform calculations and transformations of existing fields. The results are then filtered based on those outputs. Filtering and faceting are powerful search tools. They help end-users and data consumers, like retrieval augmented generation (RAG) search. These features make it easier to find relevant data in large document and data sets. They also assist with log and data processing, as well as geospatial processing.
4. What Documents are Most Relevant?
Lastly, Solr ranks search results based on relevance models. These models determine how relevant a specific search result, field or match type is to a user’s search query. Search relevance typically measures search quality. However, it’s highly subjective to the user’s intent and source content. Users consider search results more relevant when they include content that directly answers or relates to their search query.
Solr includes robust relevance modeling options that can boost or de-prioritize specific search results based on specific fields, content format, search filters and more. Solr also includes the ‘Learn to Rank’ machine learning module that can rerank results before they’re sent to the user so the most relevant results are shown first.
5. Customizing Solr
Solr is easy to get started with and works effectively out-of-the-box. Solr can be further customized and adapted for refined search behavior, diverse content indexing as well as machine learning and AI workflows.
Customizing Solr to fit your specific content and data can provide better relevance and search results. This helps users quickly find answers to their questions and increases their engagement. Other customizations include third-party integration with public and private content and data sources. This allows for secure and compliant searches.
What Can I Build With Solr?
Solr is typically used as a large-scale text search platform, but it can also be integrated into larger products, tech stacks and data processing workflows. Solr APIs, combined with Zookeeper and other orchestration methodologies enable full DevOps support, deployment, isolation and management within your existing cloud or server ecosystem.
- Website Search
Solr excels in website search applications with the included web services and APIs, as well as many third-party integrations for popular CMSs such as Sitecore and Drupal - Product Catalogs & eCommerce
Solr can handle large volume product catalog data, including product descriptions, geographic location and product attributes. Websites, point-of-sale systems and inventory management platforms can integrate with Solr to ensure product information stays up to date. - Enterprise Knowledge Search
Solr can be easily adapted for internal knowledge base search. It can securely integrate with document storage systems, digital asset management platforms and other access-controlled data sources while using single sign on (SSO) and other authentication methods. - Analytics, Data Search and Processing
Solr features can also be integrated with larger data processing workflows. It can be used for indexing large volumes of website content, transcript content, support documentation, customer history and more.
How Can I Use Solr Effectively?
Once implemented, Solr offers flexibility, customization and production-level resilience for distributed large scale high volume search. Since Solr is open-source it’s incredibly easy to run locally and start developing right away while still deploying to a wide range of servers, platforms and cloud providers.
Customizing Solr
Solr typically works well “out of the box,” but many Solr features and functions can be customized and configured as needed.
Some examples of Solr customization include:
- Customized content ingest for complex document formats like PDFs and Microsoft Office formats
- Image and video processing to extract features, tags, entities, and other visual information
- Acoustic fingerprinting and transcription for audio tracks, music, podcasts, and other sound recordings
- Natural language processing
- Vector search for semantic understanding and discovery
APIs and Integration
Solr includes a variety of API endpoints for basic features like indexing content and querying search results and more advanced operations for managing how Solr works and the underlying Solr environments and infrastructure.
DIY vs. Managed Hosting
Solr can run on a wide range of platforms and hardware that include a Java Runtime Environment or Java Virtual Machine. Solr can be deployed to a single host with one or more instances or nodes and deployed across multiple hosts in different regions or data centers.
Solr infrastructure can be managed in-house, including with on-prem hardware, colocated servers and data centers such as Hetzner or on cloud platforms such as Amazon Web Services, Google Cloud Platform and Microsoft Azure. Other options include managed hosting platforms that provide full Solr environments to customers while handling scaling, infrastructure management and support.
Nodes, Clusters and Multi Region
Solr is designed for scaling on single servers as well as across multiple servers and data center regions. Solr can run on an individual instance or node, and multiple nodes can be combined into a single cluster for better uptime, availability and data persistence. Distributing Solr across multiple servers and data centers can reduce latency and response time and provide backups and failovers for high availability.
Single Solr Node

Solr Cluster with Zookeeper Management

Multiregion Solr

Collections, Shards and Replicas
A collection is an index of all the document content and data that Solr has indexed. As collections grow in size they may need to be broken into smaller “shards”. Shards are individual segments of the collection that are distributed across more than one node or cluster for faster searching, indexing, and updating a very large collection of documents.
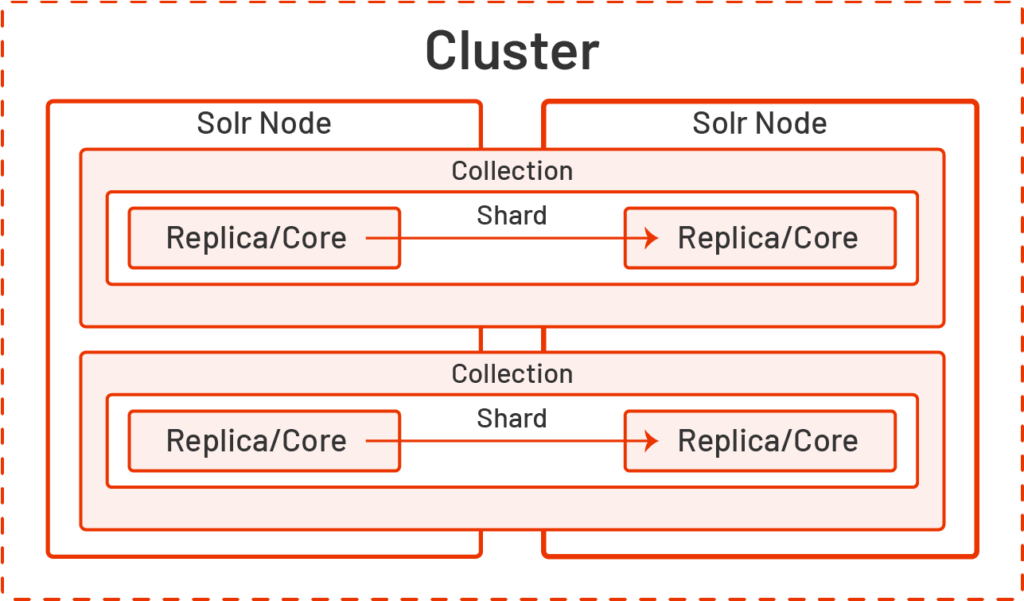
Replicas are copies of the collection or individual shards that are distributed across different nodes, clusters, and data centers. Solr will update the various replicas as needed when a document is added, changed, or removed from the collection.
Replicas and shards can add some complexity to a Solr instance but can provide faster searching and updating, minimize data loss when a node or cluster goes down, and help scale horizontally as search volume increases.
Managing Solr Infrastructure
Solr has strong support and stability from the open source community. However, Solr performance can suffer when underlying infrastructure is not properly configured or managed. Commit issues, memory outages, and incorrectly configured caches can impact Solr performance,Cloud networking problems, underprovisioned instances and data concurrency challenges can cause downtime, outages, and slower performance.
Versions, Updates, and Security
Solr is still being developed and new features, support, patches, and performance updates are added regularly. Deploying Solr in a production environment typically requires additional maintenance to ensure it and underlying services stay up to date.
How to Start Using Solr
Solr is a flexible platform that can run in a variety of environments. You can customize and extende it as needed to adapt to a wide range of content types, deployment plans, and search experiences. Due to the vast array of features Solr can be intimidating to get started with, but the Solr community and development ecosystem can help organizations plan, develop, and optimize Solr for engaging search.
Solr Infrastructure
Solr can run on any operating system that includes a Java Runtime Environment. Solr typically operates as a stand-alone web service on a dedicated instance in production environments. Solr instances will need to be scaled and provisioned appropriately to handle the expected quantity of documents and incoming search volume.
Solr Management
Solr includes basic reporting and administration features that can monitor search volume, CPU and memory usage, response latency and more. These base metrics can indicate when a Solr instance may be experiencing a large increase in volume and may need additional resources to maintain an effective search experience.
Solr stability also relies on underlying server and network configurations as well as proactive steps such as configuring back up and restore processes, setting up Zookeeper and providing disaster recovery options for high availability and reduced data loss.
Managed Search by SearchStax
SeachStax Managed Search is a hosted Solr service that makes it easier to build and scale Solr search experiences without worrying about infrastructure and Solr management. SearchStax handles the infrastructure management so you can easily develop the Solr-powered search experience without the maintenance headaches.
Get started today with our 14-day free trial to see how quickly you can start using Solr. Managed Search instances can be deployed in most major cloud providers and regions to ensure high performance service regardless of where your users and data are located.

Get Our Newsletter
The Stack is delivered bi-monthly with industry trends, insights, products and more

