At SearchStax, we continually look for ways to improve the management experience with thoughtfully designed product capabilities, because let’s face it – if we identify a tedious process that our operations team would prefer an easier way to manage, then our users must definitely think it’s tedious as well!
The need to reboot servers within a distributed systems context is a great example. Even if your team is new to SearchStax and/or Apache Solr, it’s most likely not your first encounter with managing distributed systems. SearchStax offloads the overall burden of provisioning, running, and managing Solr operations, but in some cases, your team may still experience the need to occasionally reboot Solr services. Several scenarios are listed below which go beyond general troubleshooting, such as resetting the JVM Heap Memory or conducting code change management.
Like with many distributed systems, the larger the installation, the more tedious management can get when manual operations are required. If you’re running a 10+ node cluster, triggering a Solr restart to every server in that cluster can require significant oversight on the order of hours, and be error-prone if you need to monitor and manage each restart to ensure it executes successfully and Solr recovers without issue.
Recently, we released our new Rolling Restarts feature, which provides users with the ability to reboot servers in a Dedicated Cluster deployment without having to monitor and manage each server individually. Users can go to any Dedicated Cluster deployment in their dashboard and trigger a Rolling Restart as needed.
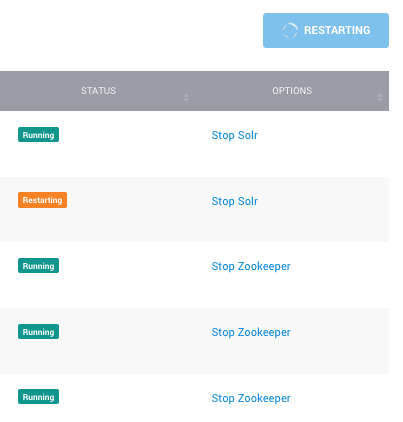
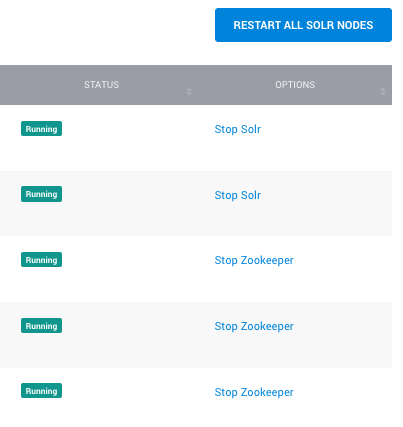
This feature is also available as part of the SearchStax Deployment API suite and can be run programmatically like any other REST API. Now users can issue a Rolling Restart command and know that servers will be restarted one-at-a-time, with back-end systems checking Solr replicas’ health on the most recently restarted server before the next server restart initializes to ensure that service uptime and availability are not impacted.
Rolling Restarts can come in handy for various use cases. Below are some common scenarios which users and even our team encounter the need for using Rolling Restarts:
- Change Management – If users ever need to update runtime libraries or various configurations, restarting Solr becomes a necessity post-update to ensure changes have been refreshed on all servers.
- JVM Heap Memory over-utilization – JVM Heap Memory utilization can sharply or steadily rise on a system. Users should always troubleshoot and optimize the underlying cause, but Rolling Restarts offer Solr users with a stopgap option to reset utilization in the meantime.
- High Transaction rates – SolrCloud clusters are effective at exchanging updates via internode communication but if resource utilization is running high, Transaction Logs (T-Logs) can build up and reduce Solr’s ability to provide near-real-time (NRT) replication. The symptom of this can be that the same search query returns different search results. Rolling Restarts can help alleviate the buildup of unprocessed T-Logs and return Solr nodes to a state of parity.
- General Troubleshooting – Rolling Restarts allow users to remove many factors which may be at play while troubleshooting a live production cluster. It’s not uncommon for users to want to trigger a Rolling Restart at the onset of ongoing incident investigations to help narrow down the root cause.
Questions?
Give Rolling Restarts a try from the dashboard or as part of your integration & delivery pipeline using the API. If you have any questions we’re always here to help at support@searchstax.com.

Get Our Newsletter
The Stack is delivered bi-monthly with industry trends, insights, products and more
Product manager who focuses on search infrastructure management and helping teams build faster with greater focus and confidence