Almost 3/4 of higher ed marketing teams publish content weekly or ad hoc, but 43% say it takes a week or more to make that content findable via onsite search.
2025’s Biggest AI Search Moments and What They Mean for Your Website
AI search changed how visitors use your site search. See SearchStax’s practical AI approach: Smart Answers, Smart Ranking and human control that builds trust.
Three Audiences, One Search Box: Why Site Search Is Critical for Government Web
Government websites rarely lack services. They lack findability. Learn why citizens, professionals and researchers all depend on site search to get things done.
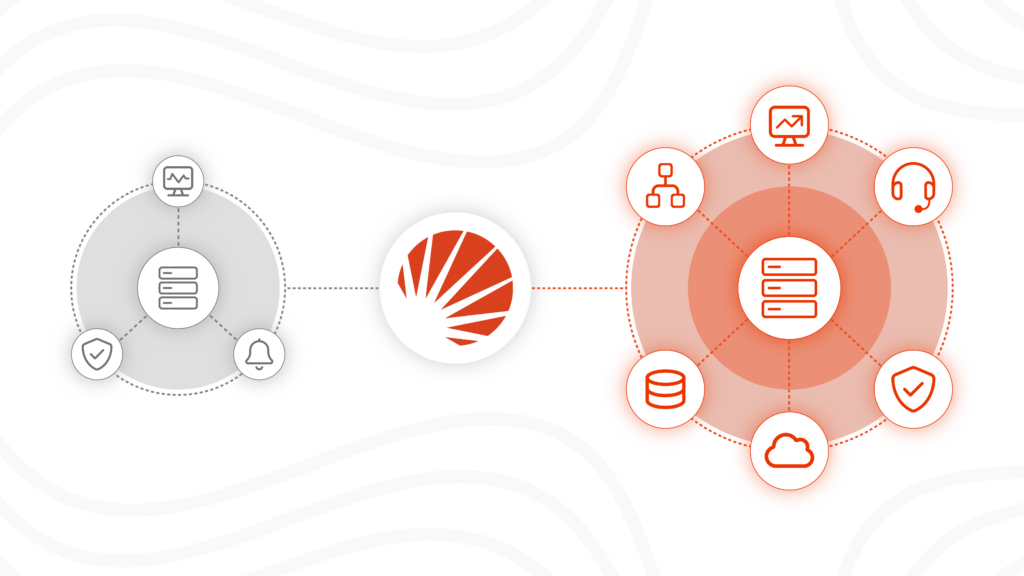
DIY Apache Solr drains engineering time and adds downtime, data loss and compliance risk. Managed Search removes Solr operational burden for production search.
New Linux Kernel Vulnerability Identified: CVE-2026-31431
Learn about the new Linux kernel vulnerability identified: CVE-2026-31431 including affected versions, risks and recommended mitigation steps to protect your deployments.
AI Has Changed Student Expectations – Your Website Needs to Catch Up
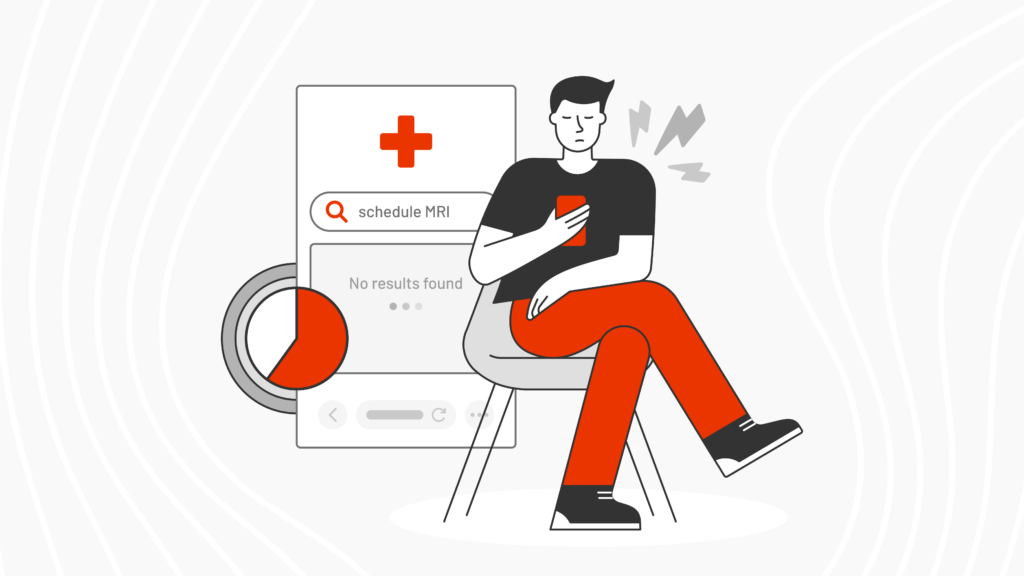
Today’s students expect instant answers. Learn why outdated university search creates an AI expectation gap and how it impacts trust, engagement and enrollment.
From Content Chaos to AI Success: Why Higher Ed Must Clean House Before Going Agentic
Agentic AI, the new breed of autonomous, decision‑making software, is built to tackle both problems, but only if the higher ed content is clean enough to feed the machine.
93% of higher ed pros say better websites drive student success–but only 19% deliver great experiences today. Explore the gap in our latest research bite.